并发编程
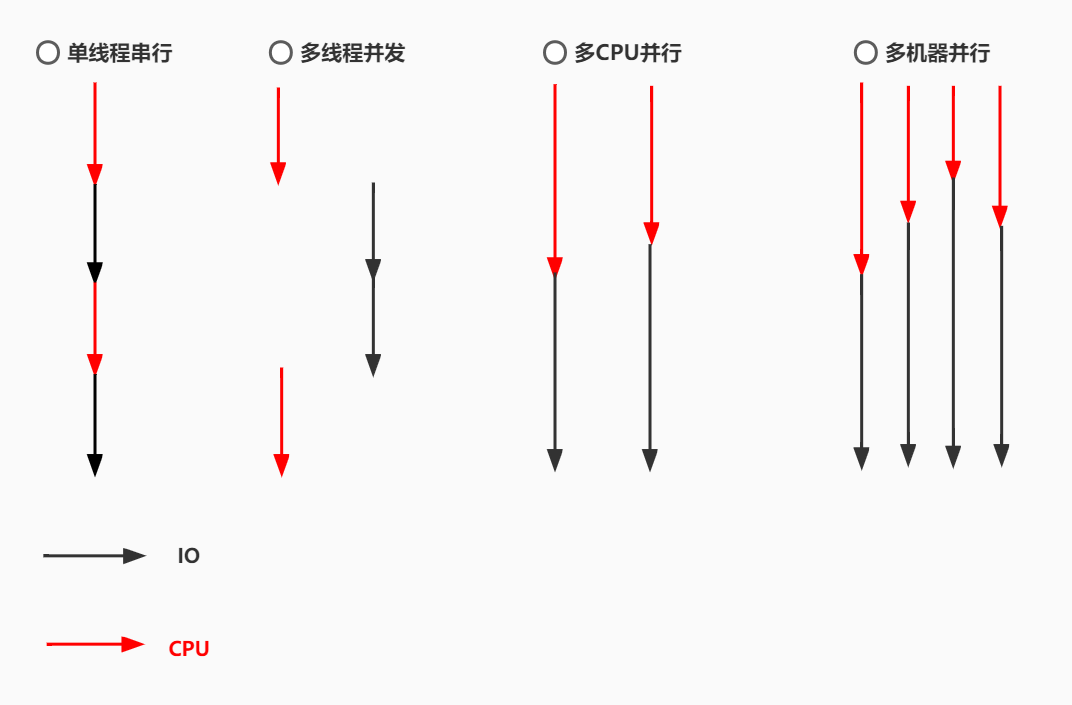
在python的爬虫,程序运行等等的应用场景中,按顺序的执行爬虫或者程序运行会花费大量的时间,通过并发来提高效率。可以通过四种方法来提升速度。分别为①单线程串行、②多线程并发、③多CPU并行、④多机器并行。CPU表示CPU的运算过程、IO指文件的读取过程,对程序来说是单线程串行,而对于单核CPU的机器来说是多线程并发CPU和CPU和IO可以同时进行,多核的CPU又可以实现多个CPU里的内核并行操作,对于机器也有并发。
①单线程串行 ②多线程并发 ③多CPU并行 ④多机器并行。
python多线程、线程、协程
进程(thread): 进程是具有独立功能程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位。
线程(thread): 线程是进程的一个实体,是cpu和分派的基本单位,它比进程更小的的独立运行的基本单位,线程自己基本不拥有系统资源,但它可与用属于一个进程的其他线程共享进程所拥有的全部资源。
协程(coroutine): 协程其实可以认为是比线程更小的执行单元,协程拥有自己的寄存器上下文和栈。我们把一个线程中的一个个函数叫做子程序,那么子程序在执行过程中可以中断去执行别的子程序,别的子程序也可以中断回来继续执行之前的子程序,这就是协程
| 多进程 | 多线程 | ||
|---|---|---|---|
| 数据共享、同步 | 数据共享复杂,需要用IPC;数据是分开的,同步简单 | 因为共享进程数据,数据共享简单,但也是因为这个原因导致同步复杂 | 各有优势 |
| 内存、CPU | 占用内存多,切换复杂,CPU利用率低 | 占用内存少,切换简单,CPU利用率高 | 线程占优 |
| 创建销毁、切换 | 创建销毁、切换复杂,速度慢 | 创建销毁、切换简单,速度很快 | 线程占优 |
| 编程、调试 | 编程简单,调试简单 | 编程复杂,调试复杂 | 进程占优 |
| 可靠性 | 进程间不会互相影响 | 一个线程挂掉将导致整个进程挂掉 | 进程占优 |
| 分布式 | 适应于多核、多机分布式;如果一台机器不够,扩展到多台机器比较简单 | 适应于多核分布式 | 进程占优 |
进程示例
主程序中的进程关系
1 | from multiprocessing import Process |
multiprocessing模块
Process
1 | Process中的构造方法为。 |
Pool
1 | Poll: multiprocessing.pool.Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]]) |
在Windows上要想使用进程模块,就必须把有关进程的代码写在if name == ‘__main__’ 内,否则在Windows下使用进程模块会产生异常。Unix/Linux下则不需要。